非推奨のAPIについて
以下記事で紹介しているAPIは、既に非推奨になっている可能性があります。詳細な内容は以下のページより参照します。

大規模言語モデル(LLM)は通常、会話の文脈を保持しないため、ユーザーとの継続的な対話において一貫性のある応答を生成することが難しい場合があります。この問題を解決するために、LangChainは「Memory」機能を提供しており、モデルが過去の会話履歴を保持し、より自然で文脈に即した対話を実現することが可能です。

メモリシステムは、基本的に「読み取り」と「書き込み」の2つの操作をサポートする必要があります。
- 最初のユーザー入力を受け取った後、コアロジックを実行する前に、チェーンはメモリシステムから読み取りを行い、ユーザー入力を補完します。
- コアロジックを実行した後、応答を返す前に、チェーンは現在の実行の入力と出力をメモリに書き込みます。これにより、将来の実行時にこれらの情報を参照することが可能となります。
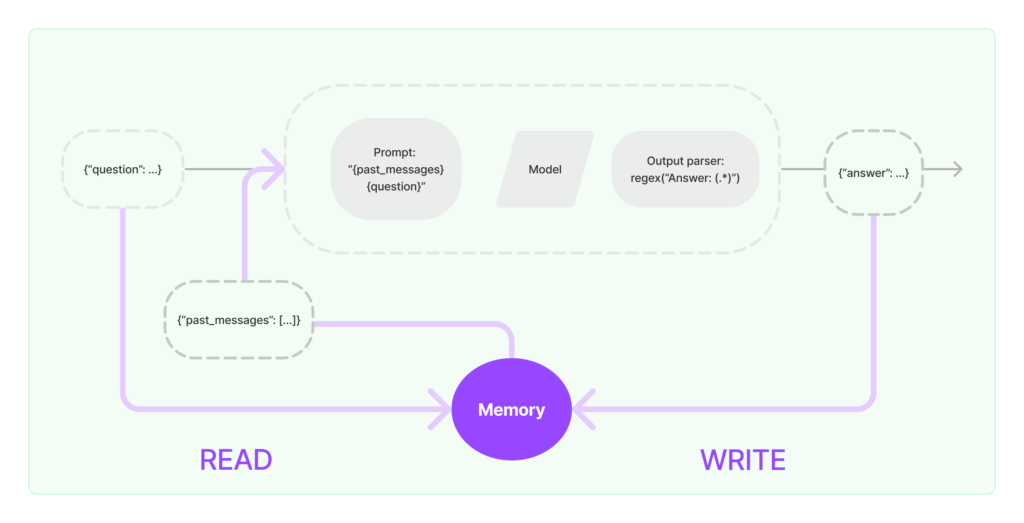
メモリクラスの種類
LangChainには、さまざまなメモリクラスが用意されており、具体的なニーズに応じて選択できます。以下に主要なメモリクラスを紹介します。
| メモリクラス名 | 説明 |
|---|---|
| ConversationBufferMemory | 会話の全履歴を保持するメモリクラスです。すべてのメッセージが順次保存され、必要に応じて過去のやり取りを参照できます。 |
| ConversationBufferWindowMemory | 直近の特定数のメッセージのみを保持するメモリクラスです。例えば、最新の5つのメッセージだけを保存し、それ以前のメッセージは破棄することで、メモリの使用量を制御します。 |
| ConversationSummaryMemory | 過去の会話を要約し、重要なポイントだけを保持するメモリクラスです。これにより、長時間の会話でも主要な情報を簡潔に把握できます。 |
| ConversationEntityMemory | 会話中に登場するエンティティ(人物、場所、物など)を抽出し、それらに関する情報を保持するメモリクラスです。これにより、特定のエンティティに関する詳細な情報を追跡できます。 |
以下に、ConversationBufferMemory を使用した簡単な実装例を示します。
import os
# 環境変数からAPIキーを取得
#api_key = "sk_..."
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("OPENAI_API_KEYが設定されていません。")
else:
print("APIキーを取得しました。")# ConversationBufferMemory クラスをインポート
from langchain.memory import ConversationBufferMemory
# ConversationBufferMemory のインスタンスを作成
# return_messages=True を指定することで、メモリからの出力が文字列ではなくメッセージオブジェクトのリストとして返されます。
memory = ConversationBufferMemory(return_messages=True)
# ユーザーからのメッセージをメモリに追加
memory.save_context({"input": "こんにちは"}, {"output": "こんにちは!今日はどのようにお手伝いできますか?"})
# AIからのメッセージをメモリに追加
memory.save_context({"input": "今日は天気がいいですね"}, {"output": "そうですね!晴れた日は気持ちが良いですね。"})
# 現在の会話履歴を取得
# return_messages=True の場合、メッセージオブジェクトのリストが返されます。
chat_history = memory.load_memory_variables({})
# 会話履歴を表示
for message in chat_history['history']:
print(f"{message.type.capitalize()}: {message.content}")以下の会話履歴が表示されます。
Human: こんにちは
Ai: こんにちは!今日はどのようにお手伝いできますか?
Human: 今日は天気がいいですね
Ai: そうですね!晴れた日は気持ちが良いですね。また、以下の方法でも会話履歴を追加できます。
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("what's up?")利用例(1)_OpenAI
以下例で、メモリを活用したLLM呼び出します。
# 必要なモジュールをインポート
from langchain_openai import OpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# 言語モデルの初期化(temperature=0で決定論的な応答を生成)
llm = OpenAI(temperature=0)
# プロンプトテンプレートを作成
# `chat_history` に過去の会話履歴が挿入される
template = """あなたは人間と会話をしている親切なチャットボットです。
これまでの会話:
{chat_history}
新しい人間からの質問: {question}
応答:"""
# PromptTemplateを作成し、指定したテンプレートを利用
prompt = PromptTemplate.from_template(template)
# ConversationBufferMemory を使用して会話履歴を保存
# memory_key="chat_history" はプロンプトの `{chat_history}` に対応
memory = ConversationBufferMemory(memory_key="chat_history")
# 会話の履歴を保存
memory.save_context(
{"input": "田中さんはUiPath Studioの開発に詳しいです"}, # ユーザーの発言
{"output": "よし、分かった"} # AIの応答
)
# LLMChain を作成し、言語モデル・プロンプト・メモリを組み合わせる
conversation = LLMChain(
llm=llm, # 言語モデル
prompt=prompt, # プロンプトテンプレート
verbose=True, # 実行時の詳細情報を表示
memory=memory # 会話の履歴を管理
)
# `question` 変数のみ渡せばよい(`chat_history` はメモリが自動で補完)
response = conversation({"question": "田中さんの専門は何ですか、詳しく教えてください。"})
# 応答を表示
print(response)
出力(VerboseがTrueですので、実行時の詳細情報も表示):
> Entering new LLMChain chain...
Prompt after formatting:
あなたは人間と会話をしている親切なチャットボットです。
これまでの会話:
Human: 田中さんはUiPath Studioの開発に詳しいです
AI: よし、分かった
新しい人間からの質問: 田中さんの専門は何ですか、詳しく教えてください。
応答:
> Finished chain.
{'question': '田中さんの専門は何ですか、詳しく教えてください。',
'chat_history': 'Human: 田中さんはUiPath Studioの開発に詳しいです\nAI: よし、分かった',
'text': ' 田中さんの専門はUiPath Studioの開発です。彼はUiPath Studioを使用して、自動化されたプロセスを作成し、ビジネスプロセスの効率を向上させることができます。また、彼はプログラミング言語やデータベースの知識も豊富で、UiPath Studioをより効果的に活用することができます。'}利用例(2)_ChatOpenAI
前のOpenAI利用例との違いは以下の通りです。ChatOpenAI + ChatPromptTemplate + MessagesPlaceholder を組み合わせることで、より高度な会話型AIを実装できる。
| 項目 | 利用例(1)_OpenAI | 利用例(2)_ChatOpenAI | 違い |
|---|---|---|---|
| 言語モデル | OpenAI | ChatOpenAI | ChatOpenAI は会話特化型 |
| プロンプトテンプレート | PromptTemplate | ChatPromptTemplate | ChatPromptTemplate の方が構造化され、役割が明確 |
| 履歴の管理 | 文字列として保存 (ConversationBufferMemory) | メッセージリスト (ConversationBufferMemory(return_messages=True)) | return_messages=True でメッセージごとに履歴を管理 |
| 会話履歴の適用 | 文字列を chat_history に埋め込む | MessagesPlaceholder を使用 | MessagesPlaceholder により履歴管理がしやすい |
from langchain_openai import ChatOpenAI
from langchain_core.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
from langchain.memory import ConversationBufferMemory
# 言語モデルの初期化
llm = ChatOpenAI()
# チャットプロンプトテンプレートの作成
prompt = ChatPromptTemplate(
messages=[
# システムメッセージ(AIの役割を定義)
SystemMessagePromptTemplate.from_template(
"あなたは人間と会話する親切なチャットボットです。"
),
# `variable_name` は、メモリ内の変数と一致する必要があります。
MessagesPlaceholder(variable_name="chat_history"),
# 人間からの新しい質問
HumanMessagePromptTemplate.from_template("{question}")
]
)
# `return_messages=True` を指定することで、MessagesPlaceholder に適合させる
# "chat_history" の変数名は MessagesPlaceholder の変数名と一致させる必要がある
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
memory.save_context({"input":"田中さんはUiPath Studioの開発に詳しいです"},{"output":"よし、分かった"})
# 会話チェーンの作成
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
conversation({"question": "田中さんの専門は何ですか、詳しく教えてください。"})出力は以下の通りです。
> Entering new LLMChain chain...
Prompt after formatting:
System: あなたは人間と会話する親切なチャットボットです。
Human: 田中さんはUiPath Studioの開発に詳しいです
AI: よし、分かった
Human: 田中さんの専門は何ですか、詳しく教えてください。
> Finished chain.
{'question': '田中さんの専門は何ですか、詳しく教えてください。',
'chat_history': [HumanMessage(content='田中さんはUiPath Studioの開発に詳しいです', additional_kwargs={}, response_metadata={}),
AIMessage(content='よし、分かった', additional_kwargs={}, response_metadata={}),
HumanMessage(content='田中さんの専門は何ですか、詳しく教えてください。', additional_kwargs={}, response_metadata={}),
AIMessage(content='田中さんは主にRPA(Robotic Process Automation)に関連する技術やツールに精通しています。具体的にはUiPath StudioというRPA開発ツールに詳しく、プロセスの自動化やワークフローの最適化において豊富な経験を持っています。また、プログラミングスキルやビジネスプロセスの理解にも優れており、顧客のニーズに合わせた効果的な自動化ソリューションを提供することが得意です。', additional_kwargs={}, response_metadata={})],
'text': '田中さんは主にRPA(Robotic Process Automation)に関連する技術やツールに精通しています。具体的にはUiPath StudioというRPA開発ツールに詳しく、プロセスの自動化やワークフローの最適化において豊富な経験を持っています。また、プログラミングスキルやビジネスプロセスの理解にも優れており、顧客のニーズに合わせた効果的な自動化ソリューションを提供することが得意です。'}Chat Messages
ほとんどのメモリモジュール(またはすべてのメモリモジュール)の基盤となる主要なユーティリティクラスの1つが ChatMessageHistory クラス です。最も基本的なメモリ管理ユーティリティ であり、単純なメッセージ履歴の保存・取得 を行います。
このクラスは、非常に軽量なラッパーであり、以下のような便利なメソッドを提供します。
HumanMessage(人間のメッセージ)を保存AIMessage(AIのメッセージ)を保存- 保存されたすべてのメッセージを取得
このクラスは、チェーン(Chain)を使わずにメモリを管理したい場合に直接使用することができます。
# 必要なモジュールをインポート
from langchain.memory import ChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.memory import ConversationBufferMemory
from langchain.chains import LLMChain
from langchain_openai import ChatOpenAI
# メッセージ履歴の初期化(過去の会話を保持する)
history = ChatMessageHistory()
# ユーザーからのメッセージを追加(過去の会話を履歴に保存)
history.add_user_message("こんにちは!今日東京の天気が晴れていますね")
# AIからのメッセージを追加(AIの応答を履歴に保存)
history.add_ai_message("こんにちは!そうですね")
# チャットプロンプトテンプレートの作成
prompt = ChatPromptTemplate.from_messages([
# 過去の会話履歴をプレースホルダーとして利用
MessagesPlaceholder(variable_name="chat_history"),
# ユーザーの新しい質問を受け取る
("human", "{input}")
])
# 会話履歴を管理するメモリを作成
memory = ConversationBufferMemory(
chat_memory=history, # `ChatMessageHistory` インスタンスを利用
memory_key="chat_history", # プロンプトの `chat_history` プレースホルダーと一致させる
return_messages=True # メッセージをオブジェクトのリストとして返す
)
# 言語モデルの初期化
llm = ChatOpenAI()
# 会話の流れを管理する LLMChain を作成
conversation = LLMChain(
llm=llm, # 言語モデル(ChatGPT)
prompt=prompt, # プロンプトテンプレート(履歴 + 新しい質問)
memory=memory, # メモリ(会話履歴の管理)
verbose=True # デバッグ情報を詳細に表示
)
# ユーザーの新しい質問を入力し、AIの応答を取得
response = conversation.predict(input="今日の東京の天気はどうですか?")
# AIの応答を表示
print(response)出力:
> Entering new LLMChain chain...
Prompt after formatting:
Human: こんにちは!今日東京の天気が晴れていますね
AI: こんにちは!そうですね
Human: 今日の東京の天気はどうですか?
> Finished chain.
今日の東京の天気は晴れで、気温は20度ほどです。気持ちの良い天気ですね!ChatMessageHistoryとその他のメモリクラスの関連
ChatMessageHistory クラスは、最も基本的なメモリ管理ユーティリティ であり、単純なメッセージ履歴の保存・取得 を行います。単独で使用可能 ですが、LangChain の多くのメモリモジュールがこのクラスを内部的に利用しています。
| クラス名 | 役割 | ChatMessageHistory との関係 |
|---|---|---|
| ChatMessageHistory | 基本的なメッセージ履歴の保存・取得を行う軽量なクラス | 会話の履歴を直接管理。多くのメモリクラスが内部で使用する |
| ConversationBufferMemory | すべての会話履歴を保持 し、チェーンに統合するメモリ | 内部的に ChatMessageHistory を使用して履歴を保存 |
| ConversationBufferWindowMemory | 直近の一定数のメッセージのみを保持(古いメッセージは削除) | 内部的に ChatMessageHistory を使用し、過去の履歴を制限する |
| ConversationSummaryMemory | 会話を要約し、履歴の負担を軽減 するメモリ | ChatMessageHistory を使用し、履歴を要約して格納 |
| ConversationEntityMemory | 会話内のエンティティ(人・場所・物など)を抽出・記憶 するメモリ | ChatMessageHistory を使用し、会話から特定の情報(エンティティ)を抽出して保持 |
ConversationBufferWindowMemory
from langchain.memory import ConversationBufferWindowMemory
# 直近3件の会話だけを保持する
memory = ConversationBufferWindowMemory(k=3)
# ユーザーとAIの会話を保存
memory.chat_memory.add_user_message("こんにちは")
memory.chat_memory.add_ai_message("こんにちは!")
memory.chat_memory.add_user_message("天気はどうですか?")
memory.chat_memory.add_ai_message("晴れです。")
memory.chat_memory.add_user_message("気温は?")
# 会話履歴の取得
print(memory.chat_memory.messages) 出力:
[HumanMessage(content='こんにちは', additional_kwargs={}, response_metadata={}), AIMessage(content='こんにちは!', additional_kwargs={}, response_metadata={}), HumanMessage(content='天気はどうですか?', additional_kwargs={}, response_metadata={}), AIMessage(content='晴れです。', additional_kwargs={}, response_metadata={}), HumanMessage(content='気温は?', additional_kwargs={}, response_metadata={})]ConversationSummaryMemory
from langchain.memory import ConversationSummaryMemory
from langchain.llms import OpenAI
# メモリの作成(会話の要約機能を持つ)
memory = ConversationSummaryMemory(llm=OpenAI())
# ユーザーの入力とAIの応答を保存
memory.save_context({"input": "私は山田です"}, {"output": "よろしくお願いします"})
memory.save_context({"input": "旅行が好きです"}, {"output": "どこに行きましたか?"})
# まとめられた履歴を取得
print(memory.load_memory_variables({})["history"])
出力:
The human introduces themselves as Yamada and mentions their love for traveling. The AI responds by asking where they have traveled.ConversationEntityMemory
from langchain.memory import ConversationEntityMemory
from langchain.llms import OpenAI
# エンティティを記憶するメモリ
memory = ConversationEntityMemory(llm=OpenAI())
# 情報の保存
memory.save_context({"input": "私は佐藤です"}, {"output": "佐藤さん、こんにちは!"})
memory.save_context({"input": "私は東京に住んでいます"}, {"output": "東京のどこですか?"})
# 記憶されたエンティティの確認
memory.load_memory_variables({"input": '鈴木さんは神奈川県の横浜市の関内のららぽーと横浜に住んでいます。教師です'})出力:
{'history': 'Human: 私は佐藤です\nAI: 佐藤さん、こんにちは!\nHuman: 私は東京に住んでいます\nAI: 東京のどこですか?',
'entities': {'鈴木さん': '',
'神奈川県': '',
'横浜市': '',
'関内': '',
'ららぽーと横浜': '',
'教師': ''}}実践:ChatGPTをクローン
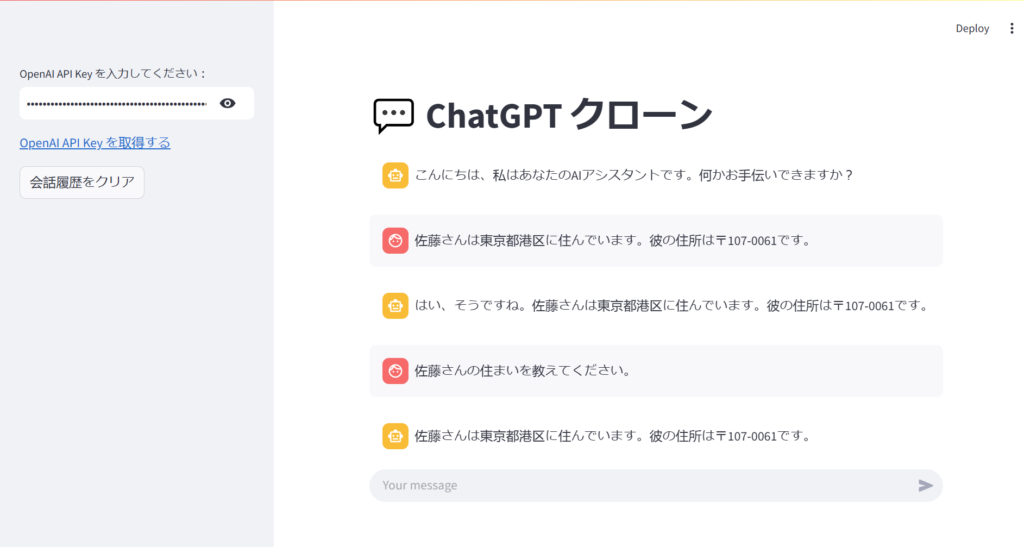
こちらでは、ChatGPTをクローンする方法を実践的に解説 し、独自の対話型AIを構築する手順 を紹介します。LangChainやStreamlitを活用し、会話の履歴を保持しながらスムーズに応答できるAIチャットボットを作成しましょう。
作成後ウェブアプリケーションは以下のイメージです。
生成AI処理
このプログラムでは、ユーザーの入力に対してAIが適切に応答し、過去の会話履歴を記憶する仕組み を実装します。LangChainのConversationBufferMemoryを活用し、文脈を理解した対話が可能なAIアシスタントを構築していきます。
# 必要なライブラリをインポート
from langchain.chains import ConversationChain # LangChain の会話管理クラス
from langchain_openai import ChatOpenAI # OpenAI の GPT モデルを利用
import os # 環境変数(APIキーの取得)用
from langchain.memory import ConversationBufferMemory # 会話の履歴を保存するためのメモリ
# ChatGPT に対するリクエストを処理する関数
def get_chat_response(prompt, memory, openai_api_key):
"""
ユーザーの入力を基に AI から応答を取得する関数。
Parameters:
- prompt (str): ユーザーの質問やメッセージ
- memory (ConversationBufferMemory): 会話履歴を管理するオブジェクト
- openai_api_key (str): OpenAI APIキー
Returns:
- response (str): AI からの応答メッセージ
"""
# OpenAI の GPT モデル(gpt-3.5-turbo)を設定
model = ChatOpenAI(model="gpt-3.5-turbo", openai_api_key=openai_api_key)
# LangChain の会話チェーンを作成(会話履歴を含む)
chain = ConversationChain(llm=model, memory=memory)
# AI にプロンプトを送信し、応答を取得
response = chain.invoke({"input": prompt})
# 取得した応答を返す
return response["response"]
# 会話の履歴を保持するメモリオブジェクトを作成
memory = ConversationBufferMemory(return_messages=True)
# 以下のコメントアウトされたコードを実行すると、ChatGPT との対話が可能になる
print(get_chat_response("ニュートンが提唱した有名な法則は?", memory, os.getenv("OPENAI_API_KEY")))
print(get_chat_response("私の前の質問は何?", memory, os.getenv("OPENAI_API_KEY")))Streamlit を使った ChatGPT クローンの UI 実装
こちらでは、Streamlit を活用して ChatGPT クローンの UI を作成する方法 を紹介します。
Streamlit は、Python で簡単に Web アプリケーションを作成できるライブラリであり、対話型の AI チャットボットを手軽に構築 することが可能です。
このプログラムでは、以下の機能を備えた シンプルなチャット UI を実装します。
✅ アプリのタイトルとインターフェースを作成
✅ サイドバーで OpenAI API Key を入力できるようにする
✅ ユーザーがメッセージを送信し、AI からの応答を受け取る
✅ 会話履歴を管理し、過去のやり取りを保持する
✅ 「会話履歴のクリア」ボタンでリセットできる機能を追加
# 必要なライブラリをインポート
import streamlit as st # Streamlit: Webアプリを作成するライブラリ
from langchain.memory import ConversationBufferMemory # 会話の履歴を管理するためのメモリ
from utils import get_chat_response # OpenAI の API を使って AI 応答を取得する関数
# アプリのタイトルを設定
st.title("💬 ChatGPT クローン")
# サイドバーの設定
with st.sidebar:
# ユーザーが OpenAI API Key を入力する欄(パスワード形式で入力)
openai_api_key = st.text_input("OpenAI API Key を入力してください:", type="password")
# OpenAI API Key を取得するためのリンクを表示
st.markdown("[OpenAI API Key を取得する](https://platform.openai.com/account/api-keys)")
if st.button("会話履歴をクリア"):
st.session_state["messages"] = [
{"role": "ai", "content": "こんにちは、私はあなたのAIアシスタントです。何かお手伝いできますか?"}]
# セッションステートに会話履歴がない場合、新しく作成する
if "memory" not in st.session_state:
# 会話履歴を保存するためのメモリを作成
st.session_state["memory"] = ConversationBufferMemory(return_messages=True)
# 初回メッセージとして AI アシスタントの挨拶を設定
st.session_state["messages"] = [
{"role": "ai", "content": "こんにちは、私はあなたのAIアシスタントです。何かお手伝いできますか?"}]
# これまでの会話履歴を順番に表示
for message in st.session_state["messages"]:
# AI またはユーザーのメッセージを表示
st.chat_message(message["role"]).write(message["content"])
# ユーザーが入力欄にメッセージを入力
prompt = st.chat_input()
# ユーザーがメッセージを入力した場合の処理
if prompt:
# OpenAI API Key が未入力の場合はエラーを表示して処理を停止
if not openai_api_key:
st.info("OpenAI API Key を入力してください")
st.stop()
# ユーザーのメッセージを会話履歴に追加
st.session_state["messages"].append({"role": "human", "content": prompt})
# 入力したメッセージを画面に表示
st.chat_message("human").write(prompt)
# AI の応答を取得する処理(ローディングのスピナーを表示)
with st.spinner("AIが考えています。しばらくお待ちください..."):
response = get_chat_response(prompt, st.session_state["memory"], openai_api_key)
# AI の応答を会話履歴に追加
msg = {"role": "ai", "content": response}
st.session_state["messages"].append(msg)
# AI の応答を画面に表示
st.chat_message("ai").write(response)これにより、ユーザーは直感的に ChatGPT クローンと対話できる環境が整っています。



