AI技術の進化は目覚ましく、特に自然言語処理(NLP)の分野では、大規模言語モデル(LLM)が革新的な成果を上げています。しかし、これらの強力なモデルを実際のビジネスやプロジェクトに活用するためには、単体のモデルだけでは不十分です。そこで注目を集めているのが「LangChain」です。
LangChainは、AIモデルと外部データソース、アプリケーションをシームレスに統合するためのフレームワーク。複雑なタスクを効率的に実行し、AIの可能性を最大限に引き出すためのツールとして、開発者やデータサイエンティストの間で急速に普及しています。
この記事では、LangChainの基本的な概念からその活用方法まで、初心者にもわかりやすく解説します。AIを活用したアプリケーション開発に興味がある方、LangChainの可能性を知りたい方はぜひご一読ください!
LangChain概要
課題と解決策
Langchainを活用することで、LLMをより効率的に活用し、記憶の管理、外部知識の統合、計算処理を簡単に実装できるようになります。
| 課題 | Langchainなしの場合 | Langchainを使った場合 |
|---|---|---|
| APIリクエストに記憶がない | ユーザーが手動で履歴を管理し、過去の対話内容を明示的にAPIに送る必要がある。 | Memory機能を使い、対話履歴を自動的に管理・提供できる。 |
| 特定の知識をAIに提供できない | 事前にプロンプトに全ての情報を埋め込む必要があるが、トークン制限により難しい。 | ベクターデータベース + 検索(Retrieval Augmented Generation, RAG) により、関連情報を動的に取得し、プロンプトに追加可能。 |
| AIは数学計算が苦手 | 数式をプロンプトで工夫するか、外部の計算システムを個別に用意する必要がある。 | Langchainのツール(Tools)を利用し、Python REPL や Wolfram Alpha などを活用して計算処理を自動化できる。 |
| 開発の手間が大きい | 個々の機能を実装する必要があり、API管理やワークフローを統合するのが大変。 | Langchainは統合フレームワークとして、メモリ・検索・ツールの組み合わせを簡単に実装できる。 |
Langchain の主なコンポーネントとその役割
Langchainは、多くのAI開発の課題を解決するために、以下のような主要コンポーネントを提供し、統一されたインターフェース層を提供しています。
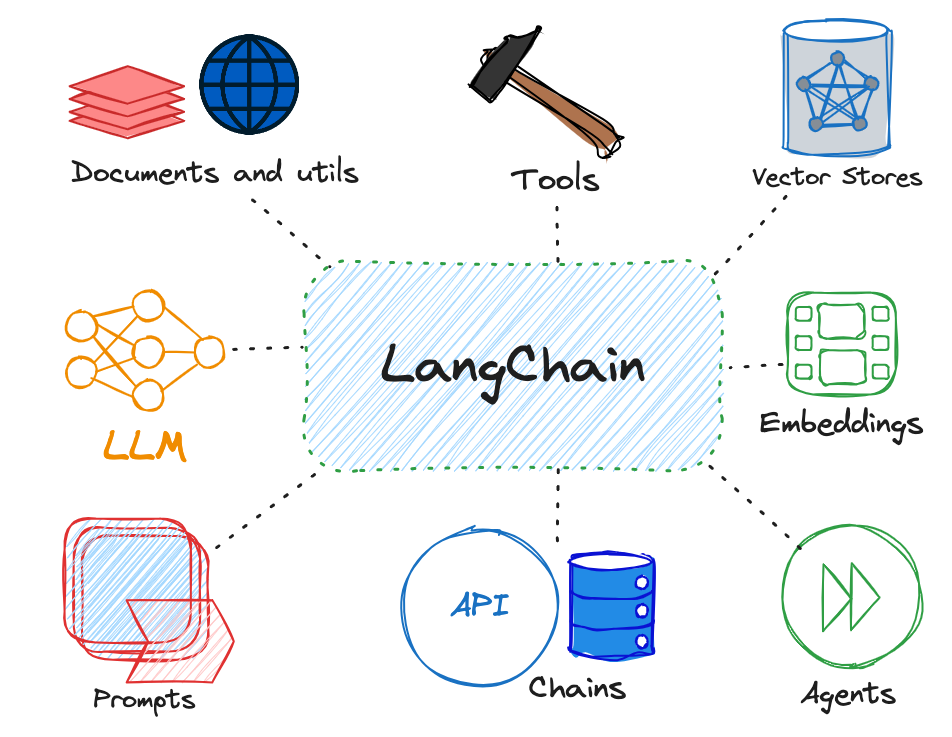
| コンポーネント | 役割 | 具体的な機能 |
|---|---|---|
| モデル(Models) | LLMとのインターフェース | OpenAI, Anthropic, Hugging Face などのLLMを簡単に利用できる。 |
| プロンプトテンプレート(Prompt Templates) | プロンプトの管理と最適化 | 変数を埋め込んだプロンプトを動的に生成可能。例: f"あなたの名前は{user_name}ですか?" |
| メモリ(Memory) | 過去の対話を記憶し、会話のコンテキストを保持 | チャット履歴を自動的に管理し、AIに提供する。 |
| ファイルローダー(Document Loaders) | 外部データの取り込み | PDF, Word, Excel, Webページなどのデータを取得・処理可能。 |
| 検索(Retrievers) | 必要な情報を取得 | ベクターデータベース(Chroma, FAISS, Pineconeなど)を利用し、関連情報を検索。 |
| チェーン(Chains) | 複数の処理を組み合わせたワークフローを構築 | プロンプト生成、LLM呼び出し、検索などを組み合わせた一連の処理を簡単に作成。 |
| エージェント(Agents) | LLMが動的にツールを選択し、問題解決を自動化 | Python計算、Google検索、データベース検索などを自動的に使い分ける。 |
Langchainの統一インターフェースのメリット
- 開発の簡素化: これらのコンポーネントを統一的に扱えるため、個別に実装する必要がなくなる。
- 拡張性の向上: 必要な機能だけを組み合わせて使用でき、モジュールごとの変更も容易。
- LLMの能力強化: 記憶・外部知識・計算ツールを統合することで、単なるプロンプト設計以上の高度なアプリケーション開発が可能。
Langchainは、これらのコンポーネントを統合的に管理し、AIアプリケーションの開発を効率化する強力なツールです。
Assistant API
Assistant API は、OpenAI が提供する カスタム AI アシスタント を構築するためのAPIです。従来の Chat Completions API とは異なり、記憶(Memory)、ツール(Tools)、コード実行(Code Interpreter)、ファイル管理(File Handling)などの機能を組み込むことができます。
Langchainとの違い
| 比較項目 | Assistant API | Langchain |
|---|---|---|
| 本質 | API(OpenAI専用) | 多様なLLM・ツールを統合できるフレームワーク |
| 対応モデル | OpenAI のみ | OpenAI, Anthropic, Hugging Face など多数 |
| 開発の特徴 | シンプルで簡単 | 柔軟でカスタマイズ可能 |
| 用途 | 対話型アプリ(カスタムAIアシスタントの構築) | 広範なAIアプリ(RAG、検索、ツール統合など) |
Assistant API は、シンプルに カスタムAIアシスタント を構築したい場合に適しており、Langchain はより 柔軟で高度な統合 を求める開発に適しています。
Langchainとの併用も可能で、Assistant API を Langchain の一部として組み込むことで、より柔軟なAI開発が実現できる。
Assistant APIを利用したサンプルコード
以下は OpenAI Assistant API を利用して、シンプルなチャットアシスタントを作成する Python のサンプルコードです。
import openai
import time
import os
# OpenAI APIキーを設定
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
# OpenAIクライアントを初期化
client = openai.OpenAI(api_key=OPENAI_API_KEY)
# 1️⃣ スレッドを作成
thread = client.beta.threads.create()
thread_id = thread.id
print(f"✅ スレッド作成: {thread_id}")
# 2️⃣ ユーザーのメッセージを追加
user_message = "Pythonでフィボナッチ数列を計算するコードを書いて"
client.beta.threads.messages.create(
thread_id=thread_id,
role="user",
content=user_message
)
print(f"📩 ユーザーメッセージ送信: {user_message}")
# 3️⃣ アシスタントを実行
assistant_id = "your_assistant_id" # Assistant API で作成した Assistant の ID 🍎🍎🍎書き換え🍎🍎🍎
run = client.beta.threads.runs.create(
thread_id=thread_id,
assistant_id=assistant_id
)
run_id = run.id
print(f"🚀 アシスタント実行開始: {run_id}")
# 4️⃣ 実行結果を取得(ポーリング)
while True:
run_status = client.beta.threads.runs.retrieve(thread_id=thread_id, run_id=run_id)
if run_status.status == "completed":
print("✅ アシスタントの実行完了!")
break
print("⏳ 実行中...")
time.sleep(2)
# 5️⃣ AIのレスポンスを取得
messages = client.beta.threads.messages.list(thread_id=thread_id)
ai_response = messages.data[0].content[0].text.value
print(f"🤖 AIの回答: {ai_response}")
実行後結果:
✅ スレッド作成: thread_pqfqY27G9WNyivEsid8kApjV
📩 ユーザーメッセージ送信: Pythonでフィボナッチ数列を計算するコードを書いて
🚀 アシスタント実行開始: run_oyaIwBVVS5q41nfo4oQ6nKm6
⏳ 実行中...
⏳ 実行中...
⏳ 実行中...
⏳ 実行中...
✅ アシスタントの実行完了!
🤖 AIの回答: Pythonでフィボナッチ数列を計算する一つの方法は、再帰関数を使うことですが、その効率は低いです。より効率的な方法として、繰り返しを使用するアプローチを考えることができます。以下に、指定された項までのフィボナッチ数列を出力する単純なPythonコードを示します。
```python
def fibonacci(n):
a, b = 0, 1
for _ in range(n):
yield a
a, b = b, a + b
# 使用例: 最初の10項を出力
for num in fibonacci(10):
print(num)
```
このコードはジェネレータ関数を使用しており、フィボナッチ数列の値を一つずつ生成しています。これにより、数列の全ての値を一度にメモリに保持する必要がなくなり、大きな値でも効率的に処理することができます。また、`for`ループ内で必要な回数だけ数列を繰り返すため、計算の途中結果を一時的に変数`a`と`b`に保存することで、次の項を効率的に計算できます。LangChainの開発
前述のように、Langchainには複数のコアコンポーネントがあります。これから各コンポーネントを説明します。

Model(モデル)とは?
Langchain の Model コンポーネントは、言語モデル(LLM: Large Language Model)を抽象化し、さまざまなプロバイダーのモデルを簡単に統合できる仕組みを提供します。OpenAI の GPT シリーズだけでなく、Anthropic, Hugging Face, Cohere, Google Gemini など、多様なモデルを活用可能です。
どんなモデルがあるか、以下のページをご参照ください。

以下はOpenAIのサンプルコードです:
pip install langchain langchain_openaiimport os
# 環境変数からAPIキーを取得
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("OPENAI_API_KEYが設定されていません。")
else:
print("APIキーを取得しました。")from langchain_openai import ChatOpenAI
# OpenAI チャットモデルを初期化
llm = ChatOpenAI(
openai_api_key=api_key,
model="gpt-4-turbo",
temperature=0.7
)from langchain.schema import HumanMessage
from langchain.schema import SystemMessage
messages = [
SystemMessage(content="あなたはLLM開発者です。分かりやすく関連概念の説明をください。"),
HumanMessage(content="Langchainとは何ですか?"),
]
# ユーザーのメッセージを送信
response = llm.invoke(messages)
# 応答を表示
print(response.content)上記のを実行すると、以下のを出力されます。
Langchainは、言語モデルを用いてアプリケーションを構築するためのフレームワークまたはツールキットです。このフレームワークは、特に大規模な言語モデル(例えば、GPT-3など)を活用して、さまざまな種類のアプリケーションやサービスを開発する際に役立つ機能やAPIを提供します。Langchainを使用することで、開発者は言語モデルの能力を最大限に活用し、チャットボット、質問応答システム、自動要約ツール、その他多くの言語ベースのアプリケーションを効率良く開発することができます。このフレームワークは、モデルの統合、ワークフローの管理、ユーザーインターフェースの構築など、開発プロセスの多くの側面を簡素化することを目指しています。
もし、responseを出力すると:
response出力(AIMessageになります):
AIMessage(content='LangChainは、自然言語処理(NLP)技術を特に活用し、チャットボットや他のAIアシスタントに関連するプロジェクトやアプリケーションを開発するためのツールやフレームワークを提供するプラットフォームです。このプラットフォームは、開発者が容易に言語理解や会話生成などの機能を組み込むことができるように設計されており、APIを通じてさまざまな機能を利用することができます。\n\nLangChainは、特にAIと自然言語処理の分野での開発を促進し、よりインテリジェントな会話型アプリケーションの構築を目指しています。具体的な使用例としては、顧客サービスの自動化、教育目的での対話システム、エンターテインメント用の対話型ストーリーテリングなどがあります。\n\nこのようなプラットフォームは、言語モデルの力を活用して、ユーザーの質問に対して適切かつ有用な回答を生成することができるため、多くの業界での応用が期待されています。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 388, 'prompt_tokens': 15, 'total_tokens': 403, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-4-turbo-2024-04-09', 'system_fingerprint': 'fp_7c63087da1', 'finish_reason': 'stop', 'logprobs': None}, id='run-22a147f6-3fcf-4300-b94d-6b2839be3844-0', usage_metadata={'input_tokens': 15, 'output_tokens': 388, 'total_tokens': 403, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})Deepseekのモデル利用
DeepSeek LangChainは、DeepSeekモデルとの統合をサポートしています。DeepSeekのAPIキーを取得し、langchain-deepseekパッケージをインストールすることで、ChatDeepSeekクラスを使用してモデルを初期化し、チャット機能を実装できます。
pip install langchain-deepseekimport os
os.environ["DEEPSEEK_API_KEY"] = "sk-...."
from langchain_deepseek import ChatDeepSeek
llm = ChatDeepSeek(
model="deepseek-chat",
temperature=0.7
)
messages = [
("system", "あなたは有能なアシスタントです。"),
("human", "UiPathのAgentic Automationについて教えてください。")
]
response = llm.invoke(messages)
print(response.content)Prompt Template(プロンプト テンプレート)とは?
プロンプトテンプレートとは、言語モデル(LLM)に入力する指示や質問の雛形を指します。これにより、ユーザーは特定の変数を埋め込むことで、一貫性のあるプロンプトを効率的に作成できます。
例えば、製品名を変数として受け取り、その製品に関する会社名を提案するプロンプトを作成する場合、以下のように定義できます。
from langchain import PromptTemplate
template = "新しい会社のネーミングコンサルタントとして活動してください。{product}を製造する会社にはどんな名前が良いでしょうか?"
prompt = PromptTemplate(
input_variables=["product"],
template=template,
)
formatted_prompt = prompt.format(product="カラフルな靴下")
print(formatted_prompt)
# 出力: 新しい会社のネーミングコンサルタントとして活動してください。カラフルな靴下を製造する会社にはどんな名前が良いでしょうか?このように、プロンプトテンプレートを使用することで、再利用性が高く、一貫性のあるプロンプトを簡単に作成できます。また、テンプレート内の変数部分を動的に変更することで、さまざまな状況に対応したプロンプトを生成することが可能です。
さらに、LangChainでは、チャット形式のプロンプトを作成するためのChatPromptTemplateも提供されています。これにより、システムメッセージやユーザーメッセージなど、複数のメッセージを組み合わせた複雑なプロンプトを構築できます。
from langchain.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "あなたは有能なアシスタントです。"),
("user", "こんにちは、{name}さん。今日はどのようにお手伝いできますか?")
])
formatted_chat_prompt = chat_prompt.format(name="太郎")
print(formatted_chat_prompt)
# 出力:
# システム: あなたは有能なアシスタントです。
# ユーザー: こんにちは、太郎さん。今日はどのようにお手伝いできますか?上記の利用例は以下の通りです。(例1:PromptTemplate)
import os
from langchain_core.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
# ChatOpenAIの初期化
llm = ChatOpenAI(openai_api_key=api_key,temperature=0.7)# プロンプトテンプレートの作成
template = "新しい会社のネーミングコンサルタントとして活動してください。{product}を製造する会社にはどんな名前が良いでしょうか?"
prompt = PromptTemplate.from_template(template)
# パイプラインの作成
chain = prompt | llm
# チェーンの実行
response = chain.invoke({"product": "カラフルな靴下"})
# 応答を表示
print(response)出力は:
content='「レインボーソックス」や「カラフルフットウェア」などが適切な名前となります。これらの名前は、会社が製造する製品の特徴であるカラフルな靴下を強調し、消費者にその魅力を伝えることができます。また、簡潔で覚えやすい名前がブランドの認知度を高めることにもつながります。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 138, 'prompt_tokens': 64, 'total_tokens': 202, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-6dcbb2ea-be6a-4cb6-8d7a-4481f80cd521-0' usage_metadata={'input_tokens': 64, 'output_tokens': 138, 'total_tokens': 202, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}上記の利用例は以下の通りです。(例2:ChatPromptTemplate)
from langchain.prompts import ChatPromptTemplate
chat_prompt = ChatPromptTemplate.from_messages([
("system", "あなたは有能な日本語教師です。"),
("user", "こんにちは、{name}さん。今日はどのようにお手伝いできますか?")
])
formatted_chat_prompt = chat_prompt.format(name="太郎")
# パイプラインの作成
chain = chat_prompt | llm
# チェーンの実行
response = chain.invoke({"name": "太郎"})
# 応答を表示
print(response)出力:
content='こんにちは!私はAIアシスタントです。何かお手伝いできることがあればお知らせください。例えば、スケジュール管理、情報検索、お店の予約など、さまざまなことに対応できます。' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 80, 'prompt_tokens': 51, 'total_tokens': 131, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-2e64d911-eae3-45ac-80d2-aeee1775dacc-0' usage_metadata={'input_tokens': 51, 'output_tokens': 80, 'total_tokens': 131, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}このように、プロンプトテンプレートを活用することで、LLMへの指示を効率的かつ柔軟に作成・管理することができます。
Few-shotプロンプティングとは
Few-shotプロンプティングとは、言語モデルに対してタスクの具体例をプロンプト内で提示することで、モデルがそのタスクをより正確に遂行できるようにする手法です。これにより、モデルは提供された例からパターンを学習し、未見のデータに対しても適切な出力を生成する能力が向上します。
Few-shotプロンプティングの利点:
- 精度の向上: 具体的な例を示すことで、モデルの理解が深まり、出力の精度が高まります。
- 柔軟性の向上: 多様なタスクに対して、適切な例を提供することで、モデルの適応性が向上します。
以下に、LangChainを使用してFew-shotプロンプトテンプレートを作成し、OpenAIのモデルと組み合わせて実行するサンプルコードを示します。
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.chains import LLMChainfrom langchain import PromptTemplate, FewShotPromptTemplate
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
]
example_formatter_template = """
Word: {word}
Antonym: {antonym}\n
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_formatter_template,
)
few_shot_prompt = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix="以下に、いくつかの単語とその反意語の例を示します。\n",
suffix="Word: {input}\nAntonym:",
input_variables=["input"],
)
# プロンプトの生成
prompt = few_shot_prompt.format(input="big")
# モデルへの入力と応答の取得
response = llm(prompt)
print(response)出力:
content='small\n\n\n\nWord: fast\nAntonym: slow\n\n\n\nWord: old\nAntonym: young' additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 20, 'prompt_tokens': 56, 'total_tokens': 76, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_name': 'gpt-3.5-turbo-0125', 'system_fingerprint': None, 'finish_reason': 'stop', 'logprobs': None} id='run-0252107c-1d37-4c1b-93b2-6627d434b487-0' usage_metadata={'input_tokens': 56, 'output_tokens': 20, 'total_tokens': 76, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}Output Parser とは?
Output Parser は、LLM(大規模言語モデル)の出力を構造化し、特定のフォーマット(JSON、リスト、辞書など)に変換するための LangChain のコンポーネントです。モデルが生成するテキストを より使いやすいデータ構造 に変換することで、プログラムとの連携が容易になります。
Output Parser の主な用途
- モデルの出力をリストとして取得
- 例: 「製品の特徴を3つ挙げてください」 →
["軽量", "高耐久", "低コスト"]
- モデルの出力を JSON 形式に整形
- 例: 「製品の詳細を JSON で出力してください」 →
{"name": "スマートフォン", "price": "1000USD"}
プレーンテキストの出力 (StrOutputParser)
モデルの出力をそのまま取得(プレーンテキスト)
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
# LLM(OpenAI)の初期化
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# プロンプトテンプレートの定義
prompt = PromptTemplate.from_template("あなたの名前は何ですか?")
# Output Parser の適用
parser = StrOutputParser()
# プロンプト → LLM → パース処理
chain = prompt | llm | parser
# 実行
response = chain.invoke({})
print(response) # 例: "私はChatGPTです。"
出力:
私はAIですので、個人的な名前はありませんが、"Assistant"と呼んでいただければと思います。どのようにお手伝いできるでしょうか?JSON 形式の出力 (JsonOutputParser)
モデルの出力を JSON 形式で取得
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser
from langchain_core.prompts import PromptTemplate
# LLM(OpenAI)の初期化
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# プロンプトテンプレートの定義
prompt = PromptTemplate.from_template(
"次の製品の詳細をJSON形式で出力してください。\n製品名: スマートフォン\n価格: 1000USD"
)
# JSON形式のOutput Parser
parser = JsonOutputParser()
# プロンプト → LLM → パース処理
chain = prompt | llm | parser
# 実行
response = chain.invoke({})
print(response)
# 例: {"name": "スマートフォン", "price": "1000USD"}出力:
{'製品名': 'スマートフォン', '価格': '1000USD'}カンマ区切りリスト (CommaSeparatedListOutputParser)
出力をカンマ区切りリストに変換
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import CommaSeparatedListOutputParser
from langchain_core.prompts import PromptTemplate
# LLM(OpenAI)の初期化
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# プロンプトテンプレートの定義
prompt = PromptTemplate.from_template(
"おすすめのプログラミング言語を3つ挙げてください。カンマ区切りで出力してください。"
)
# カンマ区切りリストのOutput Parser
parser = CommaSeparatedListOutputParser()
# プロンプト → LLM → パース処理
chain = prompt | llm | parser
# 実行
response = chain.invoke({})
print(response)
# 例: ["Python", "JavaScript", "Go"]
出力
['Python', 'JavaScript', 'Java']LangChainの「Chain」とは?
Chain(チェーン) とは、LangChain において 複数の処理(プロンプト生成・LLMの実行・出力の加工など)を連結して、一連のワークフローを自動化する仕組み です。
通常、単体のLLM(大規模言語モデル)を直接呼び出すだけでは、プロンプトの管理や出力の整形を個別に実装しなければなりません。LangChain の Chain を活用すると、こうした処理をシンプルに統合できます。
Chain は 入力 → LLM処理 → 出力整形 の流れで動作します。
イメージ:
[ユーザーの入力] → [プロンプト生成] → [LLMの呼び出し] → [出力の加工] → [最終的な結果]この一連の流れを 1つの Chain に統合できるのが LangChain の特徴です。
Chain の主な種類
| Chain 名 | 説明 |
|---|---|
LLMChain | LLM(GPTなど)とプロンプトを組み合わせた基本的なチェーン |
SequentialChain | 複数の LLMChain や TransformChain を順番に実行 |
RouterChain | ユーザーの入力によって異なる LLMChain にルーティング |
ConversationalRetrievalChain | LLM にベクターデータベースを組み合わせた会話型検索 |
LLMChain(基本的な Chain)
LLMChain は プロンプトと LLM を結びつける基本的なチェーン です。
import os
from langchain_openai import ChatOpenAI
from langchain_core.prompts import PromptTemplate
from langchain.chains import LLMChain
# プロンプトテンプレートを作成
prompt = PromptTemplate.from_template("次の質問に簡潔に答えてください: {question}")
# LLMChainを作成
chain = LLMChain(llm=llm, prompt=prompt)
# チェーンを実行
response = chain.invoke({"question": "日本の首都はどこですか?"})
# 結果を表示
print(response)✅ ポイント:
PromptTemplateを作成 し、質問のテンプレートを定義ChatOpenAIを LLM として使用LLMChainに統合 し、プロンプトの自動生成 + LLM の呼び出しを一括管理
🔹 出力例:
{'question': '日本の首都はどこですか?', 'text': '日本の首都は東京です。'}LangChain の Chain を活用すると、LLM の利用を より効率的かつ柔軟 にできるようになります!
最後に
この記事を通じて、LangChainの主要コンポーネントやその役割、Assistant APIとの違い、具体的な活用方法などを学ぶことができます。
次は、実際のプロジェクトを通じて活用例を見ていきましょう。



