近年、人工知能(AI)技術の進化が目覚ましく、特に自然言語処理(NLP)の分野では大きな進展が見られます。その中でも、OpenAIが提供する大規模言語モデル(LLM)は、テキスト生成や会話、翻訳、要約など、多岐にわたるタスクで高い性能を発揮しています。
本記事では、OpenAIのLLM APIの基本的な仕組みや活用方法について解説し、開発者やビジネスパーソンがこの技術を効果的に活用するための基礎知識を提供します。
ChatGPTとの会話-OpenAIのAPI経由
ChatGPTは、ウェブページやアプリを通じて質問を入力し、回答を得ることができます。ただし、得られた回答を加工して他のシステムに入力したり、回答の長さやスタイルを調整することはできません。
しかし、OpenAIが提供するAPIを利用すれば、これらの機能が可能になります。APIを使用することで、回答の形式や内容を自由にカスタマイズし、他のシステムと連携させることができます。
# ChatGPT APIからのレスポンスを取得する
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "あなたは英語の先生です。"},
{"role": "user", "content":"日本の英語教育の欠点は何ですか"}
],
temperature=0.1, # 創造性
max_tokens=512, # 最大のToken長さ 512
)
# レスポンスの表示
print(response.choices[0].message.content) 上記のように、ChatGPTからの回答の長さと創造性の調整ができます。
また、APIを利用することで、APIを繰り返し呼び出すことにより、大量のファイルを一括で処理することが可能になります。
さらに、自分のシステムにChatGPTのAPIを組み込むことで、これまで人が行っていた作業をAIが自動的に処理できるようになります。
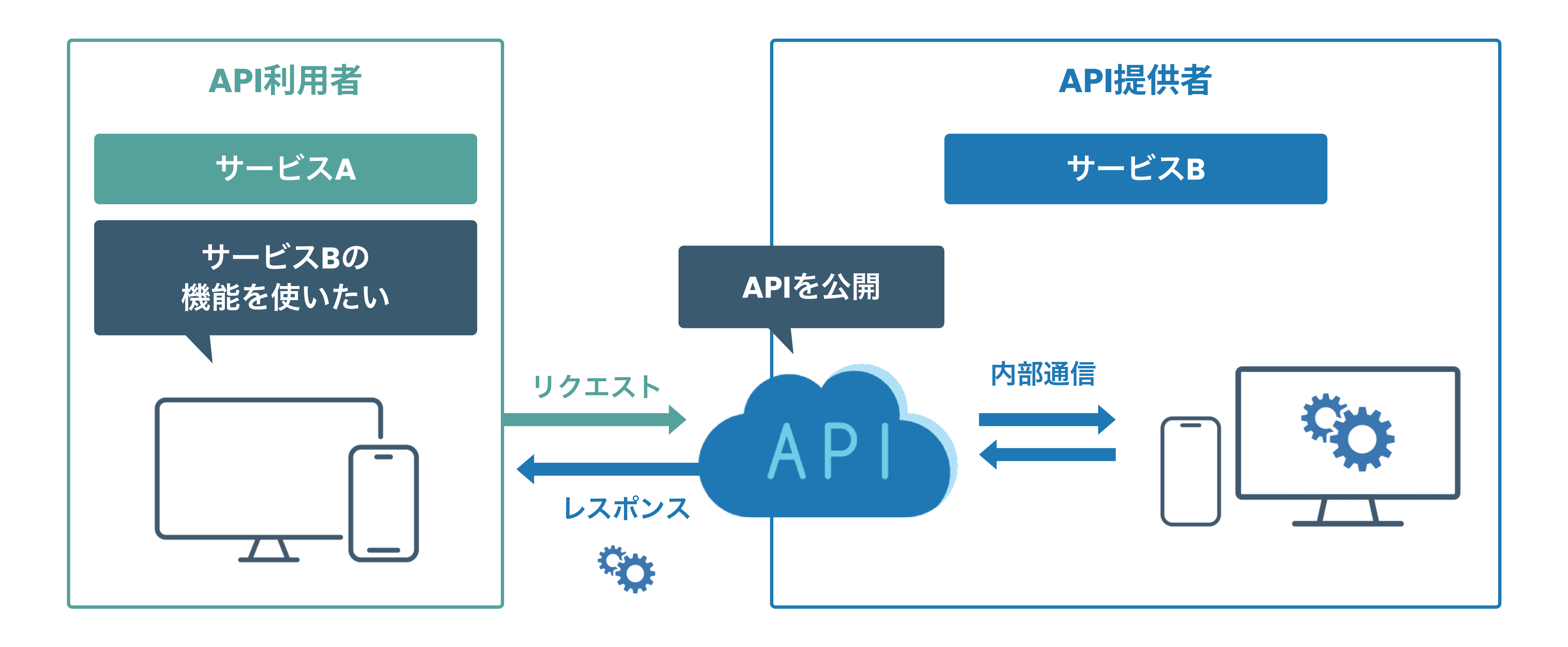
APIって何?
Web APIの仕組み
Web APIは、異なるシステム間でデータや機能をやり取りするための仕組みです。主にHTTP/HTTPSプロトコルを使って、クライアント(アプリなど)とサーバーが通信します。
基本的な流れ
- リクエスト: クライアントがサーバーに「何かをしてほしい」と要求を送ります。
- 例:
GET https://api.example.com/data(データを取得するリクエスト)
- 処理: サーバーはリクエストを受け取り、必要な処理を行います。
- 例: データベースから情報を取得する。
- レスポンス: サーバーは処理結果をクライアントに返します。
- 例:
json {"data": "Hello, World!"}
- 利用: クライアントはレスポンスを受け取り、アプリ内で表示や処理を行います。
主要な要素
- エンドポイント: APIの機能ごとにURLが用意されます。
- 例:
https://api.example.com/users
- 例:
- HTTPメソッド: リクエストの種類を指定します。
GET: データ取得POST: データ作成PUT: データ更新DELETE: データ削除
- レスポンス形式: サーバーからの返答は、主にJSON形式で返されます。

API キーの取得と利用
OpenAIのオフィシャルサイトよりAPIキーを発行して、取得します。
APIキーを利用する際、以下のように直接使用することも可能です。
import openai
openai.api_key = "こちらにOpenAIのAPIキーの明文"しかし、APIキーは他人に見せてはいけません。安全性を確保するために、WindowsやMac OSの環境変数などの仕組みを活用し、より安全な方法で利用することをおすすめします。
Windowsでは、以下の手順より設定・利用が可能です。
- Windows検索欄に「環境変数」を入力して、「システム環境変数の編集」を起動します。
- 表示された「システムのプロパティ」画面の「詳細設定」タブの一番したの「環境変数」をクリックします。
- 「システム環境変数」で「新規…」をクリックし、以下のようなのを追加します。
- 変数名:OPENAI_API_KEY
- 変数値:上記OpenAIオフィシャルサイトより取得したAPIキー
Pythonから以下のようにAPIキーを取り出せます。
import os
# 環境変数からAPIキーを取得
api_key = os.getenv("OPENAI_API_KEY")
if api_key is None:
raise ValueError("OPENAI_API_KEYが設定されていません。")
else:
print("APIキーを取得しました。")初めてのChatGPTへのリクエスト
次に、APIキーを利用して、実際にChatGPTのサーバーへリクエストを送信します。
# 必要なライブラリをインストール (事前に実行)
!pip install openai
# 必要なモジュールをインポート
import openai
import os
# 環境変数からAPIキーを取得
# "OPENAI_API_KEY"という環境変数に設定されているAPIキーを取得します
api_key = os.getenv("OPENAI_API_KEY")
# APIキーが設定されていない場合はエラーメッセージを表示してプログラムを終了
if api_key is None:
raise ValueError("OPENAI_API_KEYが設定されていません。")
else:
print("APIキーを取得しました。") # APIキー取得の成功メッセージ
# OpenAIライブラリにAPIキーを設定
openai.api_key = api_key
# ChatGPT APIにリクエストを送信してレスポンスを取得
response = openai.chat.completions.create(
model="gpt-3.5-turbo", # 使用するモデルを指定
messages=[
{"role": "system", "content": "あなたは英語の先生です。"}, # システムからの役割設定
{"role": "user", "content": "日本の英語教育の欠点は何ですか"} # ユーザーからの質問
],
temperature=0.1, # 応答の創造性や多様性の度合い(0に近いほど決まりきった応答)
max_tokens=512, # レスポンスの最大トークン長(単語数に近い概念)
)
# 取得したレスポンスの内容を表示
print(response.choices[0].message.content)API利用の課金
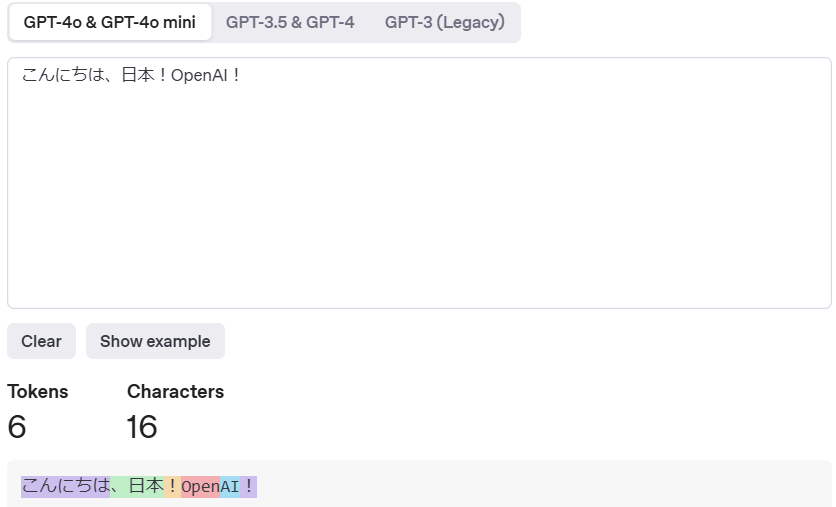
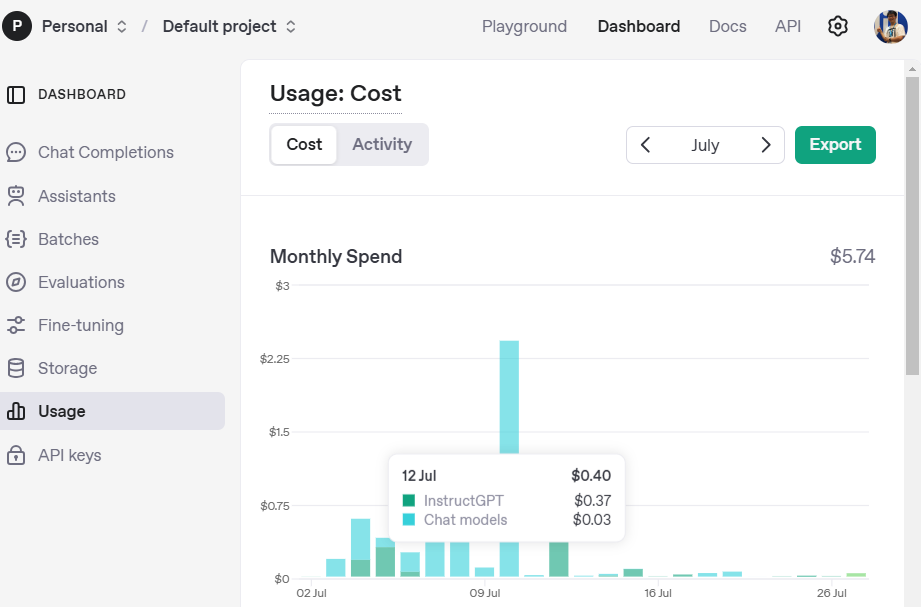
ChatGPTのAPI利用では、リクエストおよびレスポンスの両方に含まれるトークン数に基づいて課金が発生します。トークンは単語や句読点、スペースなども含めた、モデル内部でのテキスト処理単位です。
OpenAIのサイトからトークンと課金確認ができます。
トークン確認:
課金確認:
APIを利用して、トークン数の確認もできます。
!pip install tiktoken
import tiktoken
encoding = tiktoken.encoding_for_model("gpt-3.5-turbo")
len(encoding.encode("こんにちは、日本!OpenAI!")) # 8このサイトから、各モデルの課金が確認できます。
ChatGPTでのよく使うパラメータの使い方
top_p(確率マス・核サンプリング)- 説明
テキスト生成時に、選択される単語の候補を「確率が上位にある単語の集合」から制限するパラメータ。確率の合計がtop_p(0から1の値)になるように単語候補を絞り込みます。top_p = 1(デフォルト): 候補の制限なし(全候補から選択)top_p = 0.9: 上位90%の確率を占める単語から選択する
- 使い方のポイント
より「自然で多様な」応答が必要な場合に使用します。
- 説明
temperature(温度)- 説明
応答の創造性や多様性を調整するパラメータ。値が高いほどランダム性が増し、低いほど決まりきった応答になります。temperature = 0.1: ほぼ決まりきった応答temperature = 1.0: 多様性のある応答(デフォルト値)temperature > 1.0: 非常にクリエイティブで時に奇抜な応答
- 使い方のポイント
- 低め(0.0~0.3): 正確さが求められるタスク(事実情報やコード生成)に使用。
- 中間~高め(0.7~1.0): 創造的な文章生成(物語、キャッチフレーズ)に適用。
- 説明
max_tokens(トークン数の制限)- 説明
APIからのレスポンスの最大トークン数を指定します。トークン数が多いほど長い応答が返されますが、コストも増加します。- 例:
max_tokens = 100(最大100トークンまでのレスポンス) - 入力トークンとレスポンストークンの合計がモデルの上限を超えるとエラーが発生する可能性があります。
- 例:
- 使い方のポイント
- 短い回答が必要なら値を小さく設定(50~100)。
- 論文や長文が必要な場合は2000~3000程度に設定。
- 説明
frequency_penalty(頻度ペナルティ)- 説明
同じ単語やフレーズが繰り返されるのを抑制するためのパラメータです。値が大きいほど繰り返しが減少します。frequency_penalty = 0.0(デフォルト): 繰り返し抑制なしfrequency_penalty = 1.0: 繰り返しが大幅に抑制される
- 使い方のポイント
- 繰り返しが気になる場合に
0.5~1.0を設定すると改善されます。 - 特に長文生成時に役立ちます。
- 繰り返しが気になる場合に
- 説明
ベストプラクティス
- タスクに応じてパラメータを調整する
- 事実ベースの応答(正確性重視)
temperature: 0.1~0.3top_p: 1.0max_tokens: 必要に応じて100~300
- 創造的な応答(多様性重視)
temperature: 0.7~1.0top_p: 0.8~0.9max_tokens: 必要に応じて500~2000
- 事実ベースの応答(正確性重視)
- コスト管理を意識する
max_tokensを適切に設定し、無駄なトークンを抑える。- 不要な会話履歴を含めないようにする。
- 繰り返しや冗長な出力を抑える
frequency_penaltyを0.5以上に設定して改善を試みる。
- パラメータのバランスを調整する
temperatureとtop_pは同時に設定できますが、どちらか一方だけ調整することを推奨。- 大きな値を両方に設定すると、意図しない奇抜な応答になる可能性があります。
これらのパラメータを適切に組み合わせることで、様々なタスクに対応したChatGPTの応答が得られます。
Playgroundで以上のパラメータを調整して、結果の確認ができます。
プロンプト エンジニアリング
プロンプトエンジニアリングは、AIモデルがより正確で期待通りの応答を返すために、効果的な命令を設計する技術です。本ガイドラインでは、プロンプト設計の際に役立つ7つの重要なルールを説明します。これらのルールを理解し、適切に活用することで、モデルの応答精度を大幅に向上させることができます。
プロンプト文作成のベストプラクティス
以下に、各ルールについて詳細な説明と良い例・悪い例を示します。
1. 最新のモデルを使用すること
説明:
最新のモデルは、より高精度な応答や最新情報に基づいた回答が可能です。古いモデルはサポートが終了していることもあり、精度が低下します。
良い例
- 使用モデル: GPT-4
- 「GPT-4を使用して出力を生成してください」
悪い例
- 使用モデル: GPT-3.5やGPT-3(旧バージョン)
2. 命令を提示の冒頭に置き、明確に区切ること
説明:
命令が明確でないとモデルは曖昧な応答を返す可能性があります。プロンプトを視覚的に区切り、モデルが指示を認識しやすくすることが重要です。
良い例
以下の文章を要約してください:
"""
(文章本文)
"""悪い例
- 命令が曖昧: 「ちょっと要約して」
- 区切りがない場合: 文が一続きで、どこが命令か分からない。
3. 具体的な要件を提示すること
説明:
出力に求めるフォーマットや詳細を伝えないと、期待通りの結果を得られない可能性があります。
良い例
- 「{タゴール}のスタイルで、AIが人々にもたらす積極的な側面に焦点を当てた、200文字以内の励ましの短い詩を書いてください。」
悪い例
- 「要約して」だけでは、文字数や形式が不明。
- フォーマットに関する指示がない。
4. 例を示して希望する出力形式を伝えること
説明:
希望する形式を例で示すと、モデルはより正確に理解して出力を調整します。
良い例
- 以下の例のように表形式で出力してください:
| 名前 | 年齢 | 国籍 |
|-------|------|------|
| 田中 | 30 | 日本 |
悪い例
- 例がない、または曖昧。
5. シンプルなサンプルから始める
説明:
最初にシンプルな要求をし、結果が満足できない場合は詳細な指示や複雑な例を加えます。
良い例
- 最初: 「5行の要約をしてください」
- 改善後: 「5行で、具体例を含めた要約をしてください」
悪い例
- 最初から複雑すぎる要求をする。
6. 無駄な情報や曖昧な表現を避ける
説明:
余計な情報が多いと、モデルが指示を誤解することがあります。
良い例
- 「次のデータをJSON形式で出力してください」
悪い例
- 「えーっと、次のデータを、何というか、あのー、JSONみたいな形式にして」
7. 「何をしないべきか」よりも「何をするべきか」を伝える
説明:
モデルは、否定形での指示よりも肯定形の指示を正確に理解します。
良い例
- 「この情報を表形式で出力してください」
悪い例
- 「表形式以外では出力しないでください」
限定フォーマットの出力
生成AIに「限定フォーマットの出力」を指示し、指定されたフォーマットで回答を得ることができます。例えば、
3つの仮想の注文情報から構成されるリストを生成し、JSON形式で返却してください。
JSONリストの各要素には、以下の情報が含まれている必要があります:
order_id
customer_name
order_item
phone
すべての情報は文字列であること。
JSON以外のテキストは出力しないでください。JSONのみの出力であれば解析が可能ですが、以下のようにJSONデータ以外の余計な文字列が含まれている場合、解析が困難になります。
以下がJSONフォーマットの出力結果です:
{
"注文ID": "78910",
"顧客": "李四",
"住所": "上海市浦東新区100号",
"項目": [
{ "名称": "洗剤", "数量": 2 },
{ "名称": "歯磨き粉", "数量": 3 }
],
"支払い": "WeChat支払い"
}
一つの注文は、一つのJSONオブジェクトとして表現されます。OpenAIのAPIでは、新しいAPIオプション response_format を使用することで、有効なJSONオブジェクトを制限なく正確に生成できます。
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-3.5-turbo-1106",
response_format={ "type": "json_object" },
messages=[
{ "role": "user", "content": "Who won the world series in 2020?" }
]
)JSONに関しては以下のページをご参照ください。

応用例:
import json
prompt = f"""
3つの仮想の注文情報から構成されるリストを生成し、JSON形式で返してください。
JSONリスト内の各要素には、以下の情報が含まれている必要があります:
order_id
customer_name (日本人名前)
order_item (日本の野菜)
phone
すべての情報は文字列であること。
JSON以外の余分なテキストは出力しないでください。
"""
response = openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{
"role": "user",
"content": prompt
}
]
)
content = response.choices[0].message.content
json.loads(content)出力(JSONのリスト):
[{'order_id': '001',
'customer_name': '鈴木 一郎',
'order_item': 'きゅうり',
'phone': '090-1234-5678'},
{'order_id': '002',
'customer_name': '田中 かおり',
'order_item': 'トマト',
'phone': '080-9876-5432'},
{'order_id': '003',
'customer_name': '佐藤 太郎',
'order_item': 'ピーマン',
'phone': '070-6543-2109'}]Few-Shotプロンプティング
プロンプト文を書く際に、少ないサンプルを与えて適切な回答を得る方法は、「Few-Shot Learning(少数ショット学習)」と呼ばれる手法です。このアプローチでは、モデルに少数の例(サンプル)を示すことで、特定のタスクやスタイルに適した出力を生成させます。以下に、説明と具体例を紹介します。
Few-Shot Learningのポイント
- 例の選択: タスクに適した明確で簡潔な例を選びます。
- 一貫性: 例の形式やスタイルを統一します。
- 簡潔さ: 例が多すぎるとモデルが混乱するため、2〜3つの例で十分です。
例:
以下の例に従って、カジュアルな文章をフォーマルな文章に変換してください。
例1:
カジュアル: 「これ、やっておいて!」
フォーマル: 「これを実施していただけますでしょうか?」
例2:
カジュアル: 「あれ、もう終わった?」
フォーマル: 「あの件は、すでに完了しましたか?」
変換:
カジュアル: 「これ、ちょっと待って!」
フォーマル:モデルの出力:
フォーマル: 「こちら、少々お待ちいただけますでしょうか?」思考の連鎖と分割思考
思考の連鎖は、物事を一つの流れやストーリーとして考える方法です。アイデアや解決策を連続的に関連付けながら進めていくことで、全体の一貫性を保ちながら発想を広げることができます。
一方、分割思考は、課題や目標を複数のステップに分けて段階的に進める方法です。複雑なタスクを整理し、順序立てて解決するのに役立ちます。
プロンプトエンジニアリングでは、目的に応じてこれらを使い分けることが効果的です。複雑なタスクでは連続的な思考が全体像の把握に役立ち、詳細なタスクの実施には分割思考が求められます。
説明
- 思考の連鎖(シームレスシンキング)
- 物事を一つの流れで考え、つながりを意識しながら進めていきます。
- アイデアやタスクが次々に連鎖するため、ブレインストーミングや全体像の把握に向いています。
- デメリットとして、流れを意識しすぎて細部が見えにくくなる場合があります。
- 分割思考(ステップバイステップシンキング)
- 課題を小さな部分に分解し、順序立てて進めていきます。
- 分割することでタスクが明確になり、ミスを減らしやすくなります。
- デメリットは、全体像が見えにくくなる場合があることです。
例
- 思考の連鎖の例
プロンプト:
「旅行についてのエッセイを書いてください。」- 出力:旅行先の選択、経験した出来事、得た感想が流れるように一貫したストーリーとして出力されます。
- 分割思考の例
プロンプト:- 旅行先を3つ挙げてください。
- それぞれの旅行先で体験したことを詳しく説明してください。
- 旅行から学んだことをまとめてください。
- 出力:ステップごとに情報が整理され、順序立てて段階的に出力されます。
プロンプトエンジニアリングへの応用
プロンプトの設計において、連鎖思考は創造的な発想や一貫性のある文章生成に適しており、分割思考は情報整理や手順に基づいたタスクの実行に向いています。目的に応じてこれらを使い分けることで、より効果的な結果を得ることが可能です。
最後に
本記事では、OpenAIの大規模言語モデル(LLM)APIの基本的な仕組みや活用方法について解説されています。特に、ChatGPTとの対話をAPI経由で行う方法、APIキーの取得と利用、初めてのリクエストの送信方法、API利用時の課金体系、そしてプロンプトエンジニアリングのベストプラクティスなどが詳しく説明されています。これらの知識を活用することで、開発者やビジネスパーソンは、OpenAIのLLMを効果的に利用し、テキスト生成や会話、翻訳、要約などのタスクを効率的に実行できるようになります。
次の記事では、LangChainの利用を紹介します。



